事务是一组原子性的SQL命令。事务内的语句要么全部执行,要么全部不执行。
而事务的并发访问问题,则是通过锁来实现的。
第一句:MyISAM引擎不支持事务
第二句:使用事务的时候最好使用相同存储引擎的表
第三句:所以推荐使用InnoDB引擎
事务的特征ACID:
事务语法:
默认情况下MySQL开启了autocommit自动提交事务,若没有显式操作事务开启,则默认每条SQL语句都是一个事务,自动执行提交操作。
自动提交事务:
|
1 2 3 4 5 6 7 8 9 10 11 |
mysql> show variables like "autocommit"; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | autocommit | ON | +---------------+-------+ 1 row in set (0.03 sec) -- 设置自动提交 SET AUTOCOMMIT = {0 | 1}; |
显示操作事务:
如果想要显式的在事务中管理SQL,则可以使用下面的命令控制。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
-- 开启一项新的事务 BEGIN 或 START TRANSACTION -- 提交事务, 提交此事务中的所有动作 COMMIT 或 COMMIT WORK -- 提交事务, 并开始一个新的事务; 新事务的隔离级别和刚才的事务相同 COMMIT AND CHAIN -- 回滚事务, 撤销此事务内所有动作 ROLLBACK 或 ROLLBACK WORK -- 在事务中创建一个名为identifier保存点, 一个事务中可以有多个SAVEPOINT; -- 相同名字的SAVEPOINT, 则后面定义的SAVEPOINT会覆盖之前的定义。 SAVEPOINT identifier -- 删除事务名为identifier的保存点; -- 删除后的SAVEPOINT不能再执行ROLLBACK TO SAVEPOINT命令。 RELEASE SAVEPOINT identifier -- 在事务中回滚到名为identifier的保存点 ROLLBACK TO SAVEPOINT identifier -- 设置事务的隔离级别,InnoDB存储引擎提供事务的隔离级别有 -- READ UNCOMMITTED -- READ COMMITTED -- REPEATABLE READ -- SERIALIZABLE SET TRANSACTION |
脏读、幻读、不可重复读
当多个事务并发操作时,数据库就会出现这三个问题。
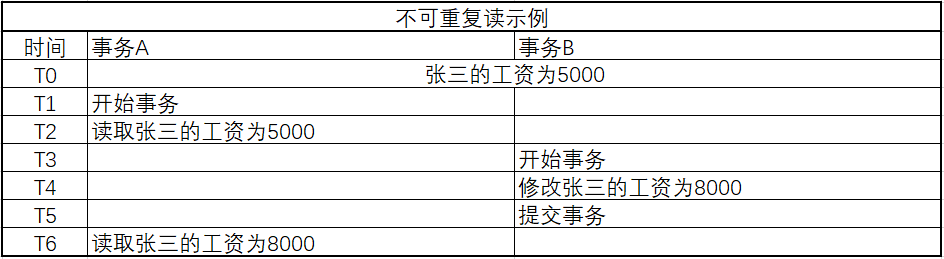
脏读(Dirty Read)
事务A进行查询时,读取到了事务B已修改尚未提交数据。
若事务B进行回滚或再次修改该数据然后提交,事务A读到的数据就是脏数据。
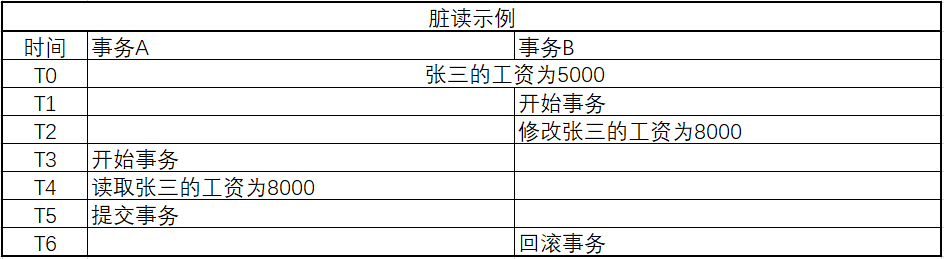
幻读(Phantom Read)
事务A进行范围查询时,事务B新增了满足该范围条件的记录。
当事务A再次按该条件进行范围查询,会查到在事务B中提交的新的满足条件的记录。
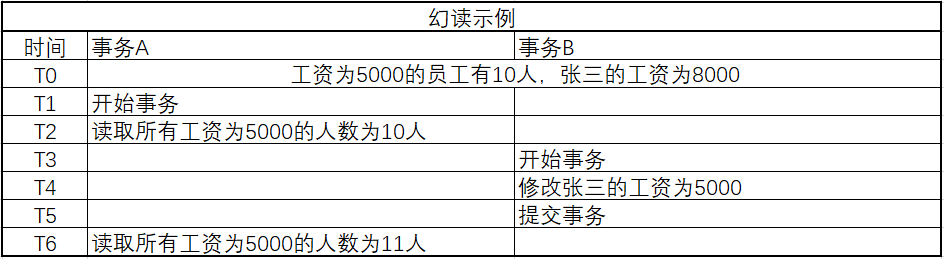
不可重复读(Unrepeatable Read)
事务A在读取某些数据后,再次读取该数据,发现读出的该数据已经在事务B中发生了变更或删除。
幻读和不可重复读的区别:
- 幻读:在同一事务中,相同条件下,两次查询出来的 记录数 不一样。
- 不可重复读:在同一事务中,相同条件下,两次查询出来的 数据值 不一样。
丢失更新问题
第一类丢失更新
事务A撤销时,把已经提交的事务B的更新数据覆盖了。
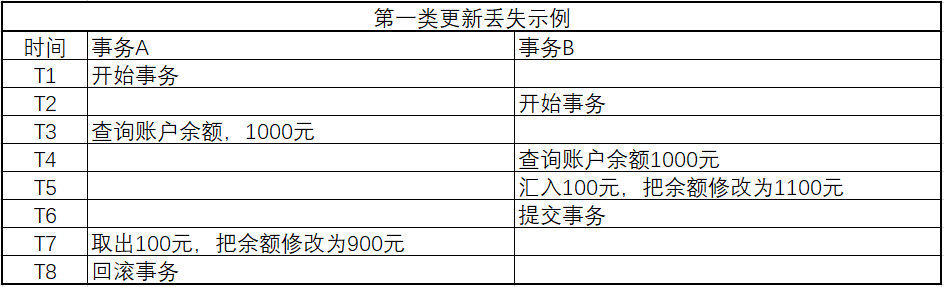
时间点T8,事务A撤销事务,余额恢复为1000,这就丢失了更新。
第二类丢失更新
事务A提交时覆盖事务B已经提交的数据,造成事务B做的操作丢失。
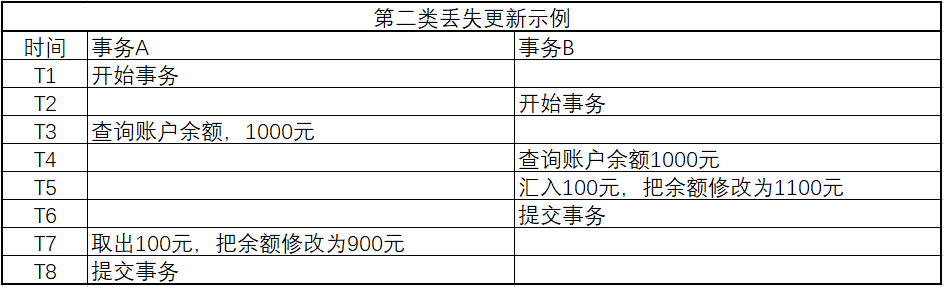
此时提交完事务后,A将余额更新为900元,覆盖了事务B的操作。
为了解决上述问题,数据库通过锁机制解决并发访问的问题。
但是直接使用锁机制管理是很复杂的,数据库基于锁机制给用户提供了不同的事务隔离级别,只要设置了事务隔离级别,数据库就会分析事务中的sql语句然后自动选择合适的锁。
事务的隔离级别
为了解决数据库中事务并发所产生的问题,在标准SQL规范中,定义了四种事务隔离级别。
每一种隔离级别都规定了一个事务中所做的修改,在哪些事务内和事务间是可见的,哪些是是不可见的。
低级别的隔离一般支持更高的并发处理。
通过修改MySQL系统参数来控制事务的隔离级别。
- MySQL5中该参数为 tx_isolation。
- MySQL8中该参数为 transcation_isolation。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
mysql> SELECT @@global.tx_isolation; +-----------------------+ | @@global.tx_isolation | +-----------------------+ | REPEATABLE-READ | +-----------------------+ 1 row in set (0.00 sec) mysql> SELECT @@tx_isolation; +-----------------+ | @@tx_isolation | +-----------------+ | REPEATABLE-READ | +-----------------+ 1 row in set (0.00 sec) |
事务的四种隔离级别
- 未提交读(Read Umcommitted),所有事务可以看到其他事务未提交的修改。
- 已提交读(Read Committed),事务之间只能看到彼此已提交的修改。
- 可重复读(Repeatable Read),同一事务中多次查询会看到相同的数据行。
- 序列化(Serializable),最高级别隔离,事务串行执行,前一个事务执行完,后一个事务执行。
不同隔离级别存在的对应问题:
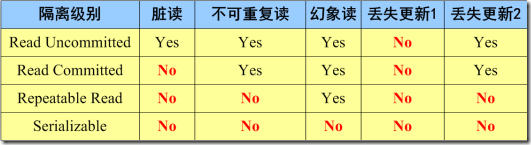
MySQL默认的事务级别就是 可重复读(Repeatable Read)。
如何保证 Repeatable Read级别绝对不产生幻读?
在SQL中加入 for update (排他锁) 或 lock in share mode (共享锁)语句实现。
就是锁住了可能造成幻读的数据,阻止数据的写入操作。MySQL的 锁相关的内容会在后面的篇章内详细介绍。
分布式XA事务
MySQL从5.0.3版本开始支持分布式事务,只支持InnoDB引擎。
具体的…暂时不想讨论。
MySQL的三种锁
- 表级锁,开销小,加锁快,不会出现死锁;冲突概率高,并发低。
- 页级锁,会出现死锁,并发量一般。
- 行级锁,开销大,加锁慢,会出现死锁;冲突概率低,并发高。
我们一般会以应用的特点来说哪种锁更合适。
仅讨论锁的角度,表级的锁适合以查询为主的Web应用,行级锁适合有大量索引的在线事务处理系统。
MyISAM 和 Memory存储引擎采用的是表级锁。
InnoDB既支持表级锁,也支持行级锁。
页级锁出现在BDB引擎,这里不讨论,不关注。
MyISAM锁的语法:
MySQL的表级锁有两种模式:表共享读锁(Table Read Lock)和表独占写锁(Table Write Lock)。
使用 lock table table_name {read | write} 命令可以对表加锁;解锁表时可以用 unlock tables 命令。
执行Lock Tables后,只能访问显式加锁的表,不能访问未加锁的表,且需要一次性锁定所有的用到的表。
|
1 2 3 4 5 6 7 8 9 10 |
-- section 1 mysql> lock table pseudohash read; Query OK, 0 rows affected (0.00 sec) mysql> unlock tables; Query OK, 0 rows affected (0.00 sec) -- section 2 mysql> INSERT INTO pseudohash(url) values("http://oj.tk-xiong.com"); Query OK, 1 row affected (9.77 sec) |
看到先加上表读锁,然后写入数据,一直卡住;解锁表后,插入成功。
InnoDB行锁模式及加锁方法
InnoDB实现了下面两种类型的行锁:
- 共享锁(读锁)(S):允许一个事务读一行,阻止其他事务获得相同数据集的排他锁。
- 排他锁(写锁)(X):允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享读锁和排他写锁。
另外为了实现多粒度锁机制(行锁和表锁共存),还有两种内部使用的意向锁(Intention Lock)。
- 意向共享锁(IS):事务打算给数据行加行共享锁,必须先取得表的IS锁。
- 意向排他锁(IX):事务打算给数据行加行排他锁,必须先取得表的IX锁。
锁模式的兼容情况:
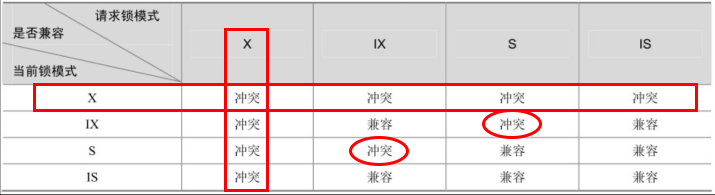
如何记住这张表很简单,排他锁和其他锁都冲突,意向排他锁和共享锁冲突。
如果一个事务请求的锁模式与当前的锁兼容,InnoDB就将请求的锁授予事务;如果不兼容,该事务就要等待锁释放。
意向锁是InnoDB自动加的,不需要用户操作、干预。
对于Update、Delete、INSERT语句,InnoDB会自动给涉及到的数据集加排他锁(X)。
对于SELECT语句,InnoDB不会加任何锁,需要在语句中显式加锁。
在MySQL5.7之前的版本,一般使用如下语句:
- 共享锁:SELECT … IN SHARE MODE
- 排他锁:SELECT … FOR UPDATE
在MySQL5.7中,排他锁没有变化,共享锁修改如下:
- 共享锁:SELECT … LOCK IN SHARE MODE
到了MySQL8.0,虽然它向下兼容,但是都有了一定变化
- 共享锁:SELECT … FOR SHARE
- 排他锁:SELECT … FOR UPDATE [NOWAIT | SKIP LOCKED]
在加排他锁时,如果遇到锁等待,那么session默认会等待50s,这在高并发的应用系统中,一旦出现对于热点行的争用,将会造成连接数的快速增加,甚至超过最大连接数。
为了解决并发问题,在MySQL8.0中排他锁FOR UPDATE后面增加了两个选项,SKIP LOCKED 和 NOWAIT,这样可以一定程度上避免这种情况。
- NOWAIT选项发现有锁等待后会立即返回错误,不用等到锁超时。
- 特殊情况下SKIP LOCKED可以用来跳过被锁定的行,直接更新其他行,但是可能造成更新结果不符合预期。
InnoDB行锁实现方式
InnoDB行锁是针对索引加的锁,不是针对记录加的锁。
它是通过给索引上的索引项加锁来实现的。
如果没有索引,InnoDB将通过隐藏的聚簇索引来对记录加锁。
InnoDB行锁分为3种情形:
- 记录锁(Record Lock):对索引项加锁。
- 间隙锁(Gap Lock):对索引项之间的“间隙”、第一条记录前的“间隙”或最后一条记录后的间隙加锁。
- Next-key Lock:前两种的组合,对记录及其前面的间隙加锁。
这种行锁的实现特点意味着:
- 如果不通过索引条件检索数据,那么InnoDB将对表中所有记录加锁,实际效果跟表锁一样。
- 如果使用相同的索引键,即使是访问不同行的记录,也会出现锁冲突。
- 当表有多个索引的时候,不同的事务可以使用不同的索引锁定不同的行。
- 即使在条件中使用了索引字段,也可能不使用索引,从而会对所有记录加锁。(索引条件不满足的情况)
Next-Key锁
当我们使用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁;
对于键值在条件范围内,但并不存在的记录,叫做间隙(GAP),InnoDB也会对这个间隙加锁,这种锁机制就是所谓的Next-Key锁。
InnoDB使用Next-Key锁的目的有两个:
- 防止幻读
- 满足恢复和复制的需要
对于幻读,举个例子,假设emp表中只有101条记录,其empid的值是 1,2,3…100,101,SQL语句如下:
SELECT * FROM emp WHERE empid > 100 for update;
这是个范围条件的检索,InnoDB不仅会对符合条件的empid值为101的记录加锁,也会对empid大于101的(不存在的记录)间隙加锁。
另外需要注意的是,如果使用相等条件给一个不存在的记录加锁,InnoDB也会使用Next-key锁!
比如 SELECT * FROM emp WHERE empid = 102 for update;
这种情况下也会使用Next-Key锁,此时如果插入一个 empid为201的记录,也会阻塞等待。
恢复和复制
MySQL通过BinLog记录执行成功的INSERT、UPDATE、DELETE等更新数据的SQL语句,并由此实现MySQL的主从复制。
这里要求不允许出现幻读,具体的后面讲到日志再讲解。
什么时候使用表锁
使用 LOCK TABLES 可以给InnoDB加表级锁。
建议使用表锁的两种情况:
1. 事务需要更新表中大量数据,如果使用默认行锁,不仅当前事务执行效率低,其他事务也可能长时间等待、锁冲突,这种情况下直接用表锁提高事务执行速度。
2. 事务涉及多个表,执行复杂,容易引起死锁造成大量事务回滚。这种情况下一次性锁定所有需要的表从而避免死锁问题,减少事务回滚带来的开销。
另外,如果应用中这两种事务过多的情况下,建议使用MyISAM,而不是InnoDB。
使用表锁需要注意的两点:
1. 表锁并不是由InnoDB存储引擎层管理的,而是其上一层MySQL Server负责的。
仅当 autocommit=0、innodb_table_locks=1时,InnoDB层才能知道MySQL加的表锁,MySQL Server才能感知到InnoDB加的行锁,这种情况下,InnoDB才能自动识别涉及表级锁的死锁。否则InnoDB将无法自动检测并处理这种死锁。
2. 加表锁时,要将autocommit设置为0,否则MySQL不会给表加锁。
事务结束前,也不要用UNLOOK TABLES释放表锁,因为UNLOOK TABLES会隐含地提交事务。
COMMIT 或 ROLLBACK也并不能用于释放表级锁,正确的操作是UNLOOK TABLES;
所以正确的流程应该是:
|
1 2 3 4 5 6 |
--写表t1, 读表t2 SET AUTOCOMMIT=0; LOCK TABLES t1 WRITE, t2 READ, ...; [do something with t1 and t2]; COMMIT; UNLOCK TABLES; |
关于死锁
MyISAM表锁是不存在死锁的,这是因为MyISAM总是一次获得所需的全部锁,要么全部满足,要么等待。
在InnoDB中,除单个SQL组成的事务外,锁是逐步获得的,所以就存在死锁的可能。
下面是死锁的一个例子:
在这个例子中的等待就是典型的死锁。
发生死锁后,InnoDB一般都能自动检测到,并使一个事务释放锁并回退,另一个事务获得锁,继续完成事务。
如果涉及外部锁或者涉及表锁的情况下,InnoDB并不能完全自动检测到死锁,这需要通过设置锁等待超时参数 innodb_lock_wait_timeout来解决。
这个参数并不是只用来解决死锁的问题,在并发访问比较高的情况下,如果大量事务因无法立即获取所需的锁而挂起,会占用大量的计算机资源,造成严重性能问题,甚至拖垮数据库。通过设置合适的锁等待超时时间,可以避免这种情况发生。
优化应用设计避免死锁
通常来说,死锁都是应用设计本身的问题。
通过调整业务流程、数据库对象设计、事务大小、访问数据的SQL语句绝大部分死锁都可以避免。
我们介绍几个实例:
实例一:引擎表顺序造成的死锁。
应用中,如果并发存取多个表,应尽量约定以相同的顺序来访问表,这样可以大大降低产生死锁的机会。
下面的例子中,两个session访问两个表的顺序不同,发生死锁的机会就非常高;但如果以相同的顺序来访问,死锁就可以避免。

实例二:数据操作顺序不一致造成的死锁。
批量处理数据时,如果实现对数据排序,保证每个线程按固定的顺序来处理记录,也可以大大降低出现死锁的可能。
下面的例子就是因为数据操作顺序不一致而造成了死锁。

实例三:事务应直接申请足够级别的锁。
如果要更新记录应该直接申请排他锁,而不应先申请共享锁,更新时再申请排他锁。
因为用户申请排他锁时,其他事务可能又已经获得了相同记录的共享锁,从而造成锁冲突,甚至死锁。
这里比较好理解,就不给出示例。
实例四:
Repeatable-Read隔离级别下,如果两个线程同时对相同条件记录用SELECT…FOR UPDATE加排他锁,在没有符合该条件的记录下,两个线程都会加锁成功。
应用程序发现记录尚不存在,就试图插入一条记录,如果两个线程都这么做,就可能出现死锁。
P.S. 下面的示例执行时,test表为空。

这里给出的解决方案是说,将隔离级别改为 READ COMMITTED,这样就不会有Gap锁。
疑问:写到这里的时候,我有个疑问,之前我们学习Next-Key锁时,它讲到,使用相等条件给一个不存在的记录加锁,InnoDB也会使用Next-Key锁。
这里ID=100的记录是不存在的,所以它会加一个exclusive next-key锁(查表可知),实际上是锁住了全表。
那我就想不通,第二个FOR UPDATE锁是怎么加上的。
实例五:
当隔离级别为Read-Committed时,如果两个线程都先执行SELECT…FOR UPDATE,判断是否存在符合条件的记录,如果没有就插入记录。
此时只有一个线程能插入成功,另一个线程会出现锁等待,当一个线程提交成功后,第二个线程会因为主键重复冲突出错,但是,虽然这个线程出错了,却会获得一个排他锁!这时如果有第三个线程来申请排他锁,也会出现死锁。
对于这种情况,可以直接做插入操作,然后再捕获主键重复异常,或者在遇到主键重复错误时总是执行ROLLBACK释放获得的排他锁。
尽管上面介绍了五个应用设计和优化SQL等措施,可以大大减少死锁,但是死锁很难完全避免。
因此程序设计中捕获并处理死锁异常是很好地编程习惯。