索引在MySQL中也叫做键(key),是存储引擎用于快速找到记录的数据结构。
这里主要是学习高性能MySQL记一些笔记,学习的话,建议自己读书。
索引基础
在MySQL中,存储引擎使用索引的方法大致是:先在索引中找到对应值,然后根据匹配的索引记录找到对应的数据行。
索引的类型
索引有很多种类型,可以针对不同的场景提供更好的性能。
在MySQL中,索引是在存储引擎层而不是服务器层实现的,所以并没有统一的索引标准。
不同存储引擎的索引工作方式并不一样,也不是所有的存储引擎都支持所有类型的索引。
即使多个存储引擎支持同一种类型的索引,其底层实现也可能不同。
这里我们主要介绍B树索引和哈希索引
B-Tree索引
没错,它就是B树索引。不是什么B减树,就读 B树。
当我们讨论索引的时候,如果没有特别指明类型,那说的就是它了。
它的底层实现数据结构多半是B-Tree,当然也有些除外,比如InnoDB用的是B+Tree。
存储引擎使用B-Tree的方式也不一样,比如MyISAM使用前缀压缩使索引更小,而InnoDB则按照原数据格式进行存储。
再比如,MyISAM索引通过数据的物理位置引用数据行,而InnoDB则根据主键引用数据行。
接下来我们以这个数据库表为例,举例说明B-Tree的相关信息:
|
1 2 3 4 5 6 7 |
CREATE TABLE People( last_name VARCHAR(50) NOT NULL, first_name VARCHAR(50) NOT NULL, dob DATE NOT NULL, gender ENUM("m", "f") NOT NULL, KEY(last_name, first_name, dob) ); |
执行SQL语句,生成下表。

我们关注索引部分,它的类型是BTREE,包含了last_name,first_name,dob三列的值。
下图显示了B+Tree索引是如何组织数据的存储的。
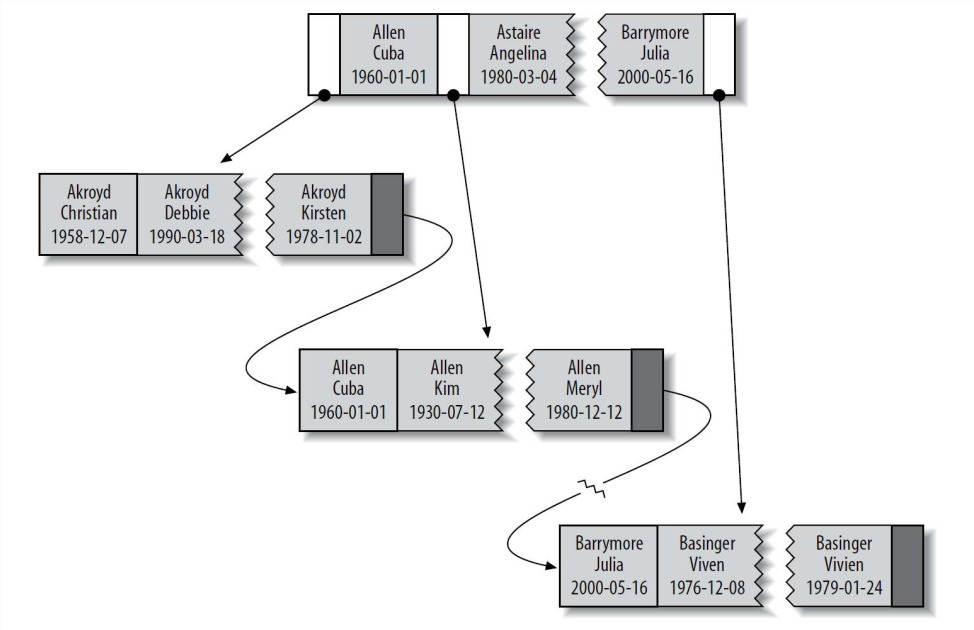
索引对多个值排序的依据是CREATE TABLE语句中定义索引的顺序,比如最后有两个 Basinger Viven同名,那就根据生日来排序。
支持B-Tree索引的查询类型
- 全值匹配:和索引中所有列进行匹配。比如我们查找Cuba Allen、生日为1960-01-01的人。
- 匹配最左前缀:和索引中第一列进行匹配。比如查找所有姓为Allen的人。
- 匹配列前缀:也可以只匹配某一列的值开头部分。比如我们查找所有姓为J开头的人。
- 匹配范围值:或者可以查找所有姓在Allen和Barrymore之间的人。
- 精确匹配某一列并范围匹配另外一列:可以查找姓为Allen,名为字母K开头的人。即第一列全匹配,第二列范围匹配。
- 只访问索引的查询:覆盖索引
BTree索引的限制:
1. 如果不是按照索引的最左侧列开始查找,则无法使用索引。比如:
- 我们无法通过索引查找名为Bill的人。
- 我们无法查找特定某一天出生的人。
- 无法查找姓以某个字母结尾的人(比如查找last_name为字母K结尾的人)。
2. 不能跳过索引中间的列。
比如我们无法查找姓为Allen且生日为1960-01-01的人,在这种情况下只能使用索引的第一列。
3. 如果查询中有某个列的范围查询,则其右边所有列都无法使用索引优化查找。
比如 WHERE last_name=’Smith’ AND first_name LIKE ‘J%’ AND dob = ‘1976-12-23’
这个查询只能使用索引的前两列,因为LIKE是一个范围条件。
哈希索引(Hash Index)
哈希索引基于哈希表实现,存储引擎针对每一行数据计算一个哈希值,所以只有精确匹配索引所有列的查询才有效。
哈希索引将所有的哈希值存储在索引中,同时在哈希表中保存指向每个数据行的指针。
Memory引擎
在MySQL中,只有Memory引擎显式支持哈希索引,它也是Memory引擎表的默认索引类型。
对于Memory引擎来说,如果多个列的Hash值相同,索引会以链表的方式存放多个记录指针到同一个哈希条目中。
当然Memory引擎也同时支持B-Tree索引。
接下来我们看下面的例子:
|
1 2 3 4 5 |
CREATE TABLE hashPeople( first_name VARCHAR(50) NOT NULL, last_name VARCHAR(50) NOT NULL, KEY USING HASH(first_name) ) ENGINE = MEMORY; |
然后我们给数据库加一些数据。
|
1 2 3 4 |
INSERT INTO `hashPeople`(`first_name`, `last_name`) VALUES('Arjen', 'Lentz'); INSERT INTO `hashPeople`(`first_name`, `last_name`) VALUES('Baron', 'Schwartz'); INSERT INTO `hashPeople`(`first_name`, `last_name`) VALUES('Peter', 'Zaitsev'); INSERT INTO `hashPeople`(`first_name`, `last_name`) VALUES('Vadim', 'Tkachenko'); |
最终我们生成的表结构如下:

我们关注索引部分,它生成的索引类型是HASH,字段只有first_name。
假设我们现在要找到名字为Peter的人的姓氏,查询语句如下;
|
1 |
SELECT last_name FROM hashPeople WHERE first_name = 'Peter' |
那么MySQL会先计算‘Peter’的哈希值,然后使用该值找到对应的记录指针,最后比较找到的first_name是否的确为‘Peter’,确保就是要查找的行。
因为索引自身只需要存储对应的哈希值,所以索引的结构十分紧凑,查找速度也很快(这里开销不是O(1),而是哈希函数的开销)。
但是哈希索引也有自身的限制:
1. 哈希索引只包含哈希值和行指针,不存储字段值,所以不能用索引中的值来避免读取行。
2. 哈希索引数据并不按照索引值顺序存储,所以无法用于排序。
3. 哈希索引不支持部分索引列匹配查找,因为它使用索引列的全部内容来计算哈希值。比如我们建立一个(A, B)的哈希索引,那么查询数据只有A,则无法使用该索引。
4. 哈希索引只支持等值比较查询,包括 =,IN(), <=>,也不支持范围查询,例如 WHERE price > 100。
5. 访问哈希索引的数据非常快,除非有很多哈希冲突。当出现哈希冲突时,存储引擎必须遍历链表中的所有行指针,逐行比较找到符合条件的行。
6. 哈希冲突很多时,维护代价也很高。比如我们要删除一行,存储引擎就必须遍历对应哈希值链表中的每一行,找到并删除对应行。
因为存在这些限制,哈希索引就只适用于特定的场景,而一旦选择了合适的场景,它带来的性能提升也十分显著。
InnoDB引擎
它有一个功能叫做“自适应哈希索引”(Adaptive hash index)。当InnoDB注意到某些索引值被使用的非常频繁时,它会在内存中基于B-Tree索引子上再建立一个哈希索引,这样就让B-Tree索引也具备哈希索引的一些优点,比如快速查找。
这个功能完全是引擎内部不受用户控制的行为,不过如果有必要,完全可以关闭该功能。
创建自定义哈希索引
如果存储引擎不支持哈希索引,则可以模拟像InnoDB一样创建哈希索引。
思路很简单,在B-Tree的基础之上创建一个伪哈希索引,这和真正的哈希索引不同。
我们使用B-Tree进行查找,但是查找的不是键本身,而是计算出来的哈希值,我们需要在WHERE子句中手动指定哈希函数。
比如我们建立下面的表:
|
1 2 3 4 5 6 |
CREATE TABLE pseudohash( id INT UNSIGNED NOT NULL AUTO_INCREMENT, url VARCHAR(255) NOT NULL, url_crc INT UNSIGNED NOT NULL DEFAULT 0, PRIMARY KEY(id) ); |
这里我们使用CRC32做哈希函数,在插入和更新时需要维护哈希值url_crc列。所以我们再建立两个触发器:
|
1 2 3 4 5 6 7 8 9 |
mysql> DELIMITER // mysql> CREATE TRIGGER pseudohash_crc_ins BEFORE INSERT ON pseudohash FOR EACH ROW BEGIN SET NEW.url_crc=crc32(NEW.url); END;// Query OK, 0 rows affected (0.01 sec) mysql> CREATE TRIGGER pseudohash_crc_upd BEFORE UPDATE ON pseudohash FOR EACH ROW BEGIN SET NEW.url_crc=crc32(NEW.url); END;// Query OK, 0 rows affected (0.00 sec) mysql> DELIMITER ; |
…
这里需要注意的是,我使用非root账户操作,创建触发器的时候报错了,错误码是1419 :
ERROR 1419 (HY000): You do not have the SUPER privilege and binary logging is enabled (you *might* want to use the less safe log_bin_trust_function_creators variable
提示要设置log_bin_trust_function_creators参数。
先登录root用户:mysql -u root -p
然后设置参数:
然后再切换回自己的用户就可以创建触发器了。
接下来我们插入一条数据:
|
1 |
INSERT INTO `pseudohash`(`url`) VALUES ('http://blog.tk-xiong.com') |
然后获取数据:(因为我是虚拟机和phpMyAdmin混用,所以给出的代码不尽相同)
|
1 2 3 4 5 6 7 |
mysql> SELECT * FROM pseudohash; +----+--------------------------+-----------+ | id | url | url_crc | +----+--------------------------+-----------+ | 1 | http://blog.tk-xiong.com | 164220712 | +----+--------------------------+-----------+ 1 row in set (0.00 sec) |
然后我们更新一下url的值,看看触发器如何维护哈希索引的。
|
1 2 3 4 5 6 7 8 9 10 11 |
mysql> UPDATE pseudohash SET url='http://blog.tk-xiong.com/' WHERE id=1; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> SELECT * FROM pseudohash; +----+---------------------------+------------+ | id | url | url_crc | +----+---------------------------+------------+ | 1 | http://blog.tk-xiong.com/ | 1282388961 | +----+---------------------------+------------+ 1 row in set (0.00 sec) |
然后给url_crc增加一个索引。
|
1 2 3 |
mysql> ALTER TABLE pseudohash ADD INDEX ind_t_url_crc(url_crc); Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0 |
接下来我们要查找url为http://blog.tk-xiong.com/的字符串。
|
1 2 3 4 5 6 7 |
mysql> SELECT * FROM pseudohash WHERE url_crc=CRC32("http://blog.tk-xiong.com/") AND url="http://blog.tk-xiong.com/"; +----+---------------------------+------------+ | id | url | url_crc | +----+---------------------------+------------+ | 1 | http://blog.tk-xiong.com/ | 1282388961 | +----+---------------------------+------------+ 1 row in set (0.00 sec) |
这里需要注意的是,CRC32返回的是32位整数,当索引有93000条记录时出现冲突的概率是1%。
如果数据表非常大,CRC32会产生大量的哈希冲突,这种情况下可以考虑自己实现一个64位的哈希函数。
尽量不要使用SHA1()和MD5()作为哈希函数,因为这两个函数计算出来的哈希值是非常长的字符串,会浪费大量空间,同时也会比较慢。
我们可以使用FNV64作为哈希函数,它的哈希值是64位,速度快,冲突也比CRC32少很多。
其他索引
空间数据索引(R-Tree)
MyISAM表支持空间索引,可以用作地理数据存储。
全文索引
全文索引是一种特殊类型的索引,它查找的是文本中的关键词,而不是直接比较索引中的值。
全文索引更类似于搜索引擎做的事情,而不是简单的WHERE条件匹配。
在相同的列上创建全文索引和B-Tree索引并不冲突,全文索引适用于MATCH AGAINST操作。
其他
还有很多第三方的存储引擎使用不同类型的数据结构存储索引,这里不做讲解。
索引的优点
总结索引的优点如下:
- 索引大大减少了服务器需要扫描的数据行
- 索引可以帮助服务器避免排序和临时表
- 索引可以将随机I/O变为顺序I/O。
三星索引:
- 一星:索引将相关的记录放到一起。
- 二星:索引中的数据顺序和查找中排列的数据顺序一致。
- 三星:索引中的列包含了查询中需要的全部列。
高性能的索引策略
独立的列
索引列不能是表达式的一部分。
比如下面的查询无法使用 actor_id 列的索引:
mysql> SELECT actor_id FROM sakila.actor WHERE actor_id + 1 = 5;
MySQL无法解析方程式,我们应该将索引列单独放在比较符号的一侧。
所以应该直接写成 actor_id = 4
同时还有下面类似的错误,比如我们查找最近10天的数据。
mysql> SELECT … WHERE TO_DAYS(CURRENT_DATE) – TO_DAYS(date_col) <= 10;
我们应该将 date_col 列单独放在比较符号的一侧,下面是比较好的方式:
mysql> SELECT … WHERE date_col >= DATE_SUB(CURRENT_DATE, INTERVAL 10 DAY);
这个查询使用索引不会有什么问题,但是CURRENT_DATE的引用会导致缓存失效。所以可以用具体的日期来替换它来提高性能。
mysql> SELECT … WHERE date_col >= DATE_SUB(‘2020-08-27’, INTERVAL 10 DAY);
前缀索引 & 索引选择性
有时候需要索引很长的字符串列,这样会让索引变得又大又慢。
有两种办法,一种是前面提到的哈希索引,另一种是索引字符串开头部分,也就是我们这一小节要讲的前缀索引。
前缀索引
通过索引字符串开始的部分字母,可以大大节约索引空间,从而提高索引效率,但这样也会降低索引的选择性。
另外,前缀索引虽然能让索引更小、更快,但是MySQL无法使用前缀索引做 GROUP BY 和 ORDER BY 操作。
索引选择性
索引的选择性越高,则查询的效率越高,因为选择性高的索引可以让MySQL在查找时过滤掉更多的行。
选择性=不重复的索引值(基数)/ 数据表的记录总数(#T)。
一般来说索引的选择性范围从 1/#T 到 1之间。
唯一索引的选择性是1,它有最好的索引选择性,性能也是最好的。
合适的前缀长度
我们要找到足够长的前缀保证较高的选择性,同时又不能太长,否则会浪费存储空间。
建议是让前缀索引的选择性接近索引整个列的选择性。
那么我们如何计算完整列column的选择性呢?
- SELECT COUNT(DISTINCT column)/COUNT(*) FROM table_name;
接下来我们计算前缀长度n的选择性:
- SELECT COUNT(DISTINCT LEFT(column, n))/COUNT(*) FROM table_name;
然后我们只需要选择前缀长度n和完整列选择性接近的n作为前缀长度即可。
数据分布
前面我们计算出来的仅仅是平均的选择性,存在可能的问题是数据的不均匀分布。
这种情况下就可能会针对某个查询有陷阱,需要我们更多注意。
后缀索引
这里最经典的案例就是找到某个域名的电子邮件地址。
这种情况下我们将字符串反转存储,并基于此建立前缀索引,得到的就是实际字符串的后缀索引。
然后我们通过触发器维护这种索引即可。
多列索引
根据三星索引的要求,索引中的列包含了查询中需要的全部列。
所以我们最好按照正确的顺序创建多列索引。
合适的索引顺序
在一个多列B-Tree树索引中,索引列的顺序意味着索引先按照最左列进行排序,然后是第二列,等等。
经验之谈:将选择性最高的列放到索引列最前列。
但是这样做可能有一个陷阱,就是对一些特定值的查询效率底下,那么就需要依赖工具来提取“最差”的查询,解决问题。
我们不能假设平均情况的性能也能代表特殊情况下的性能。
同时还应该考虑WHERE子句中的排序(ORDER BY)、分组(GROUP BY)、范围条件(between, >, <)
聚簇索引
聚簇索引不是一种单独的索引类型,而是一种表的数据保存方式。
不是所有的存储引擎都支持聚簇索引,这里主要讨论InnoDB引擎。
InnoDB的聚簇索引在同一个数据结构中保存了B-Tree索引和数据行,它通过主键聚集数据。
如果没有定义主键,会用唯一的非空索引代替,如果还没有,则会隐式定义一个主键。
聚簇索引的优点:
- 可以把相关的数据保存在一起。(减少磁盘I/O)
- 数据访问更快。
聚簇索引的缺点:
- 相比于内存型(Redis),其实并没有很大优势。
- 数据插入速度依赖于插入顺序。
- 更新聚簇索引列的代价很高。
- 可能面临页分裂(page split)问题。
- 行稀疏的表会导致全表扫描变慢。
- 二级索引会变大,因为保存的是行主键列。
- 二级索引需要查找两次。(二级索引叶子节点保存的是行主键值,而不是行数据物理位置)
下面我们用一张图表达聚簇索引和非聚簇索引的数据存储区别:
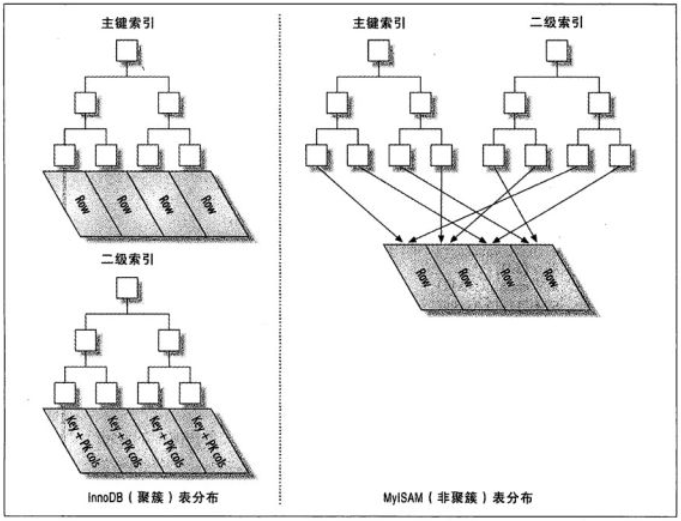
聚簇索引的所有数据(Row)都存储在主键索引中,或者说它就是表。
非聚簇索引的数据是一个表,索引指向行数据的物理位置。
覆盖索引
一个索引包含所有需要查询的字段的值,我们就称之为覆盖索引。
覆盖索引必须要存储索引列的值,所以只能用B-Tree索引做覆盖索引。
EXPLAIN的Extra列可以看到Using Index,表示使用了覆盖索引。
索引扫描
如果EXPLAIN的Type列的值为index,说明MySQL通过索引扫描来实现排序。
MySQL可以使用同一个索引,既满足排序,又可以用于查找行数据。
要求索引的列顺序和ORDER BY子句的顺序、排序方向完全一致。
前缀压缩索引
MyISAM引擎使用前缀压缩来减少索引的大小,默认只压缩字符串。
方法如下:
- 完全保存索引块第一个值
- 把其他值和第一个值比较,得到相同前缀的字节数和剩余不同后缀存储起来。
比如第一个值是perform,第二个值是performance,那么第二个值的前缀压缩之后就是“7,ance”这样的形式。
这样做的优点是节约空间
缺点是倒序查找速度变慢,无法使用二分查找等等。
冗余和重复索引
MySQL允许在相同列上创建多个索引。
重复索引指的是在相同列上按照相同顺序创建相同类型的索引。
比如我们创建如下表:
|
1 2 3 4 5 6 7 |
CREATE TABLE test( ID INT NOT NULL PRIMARY KEY, A INT NOT NULL, B INT NOT NULL, UNIQUE(ID), INDEX(ID) ) |
这里要记住,MySQL的唯一限制、主键限制都是通过索引来实现的,所以实际上我们创建了3个重复索引。
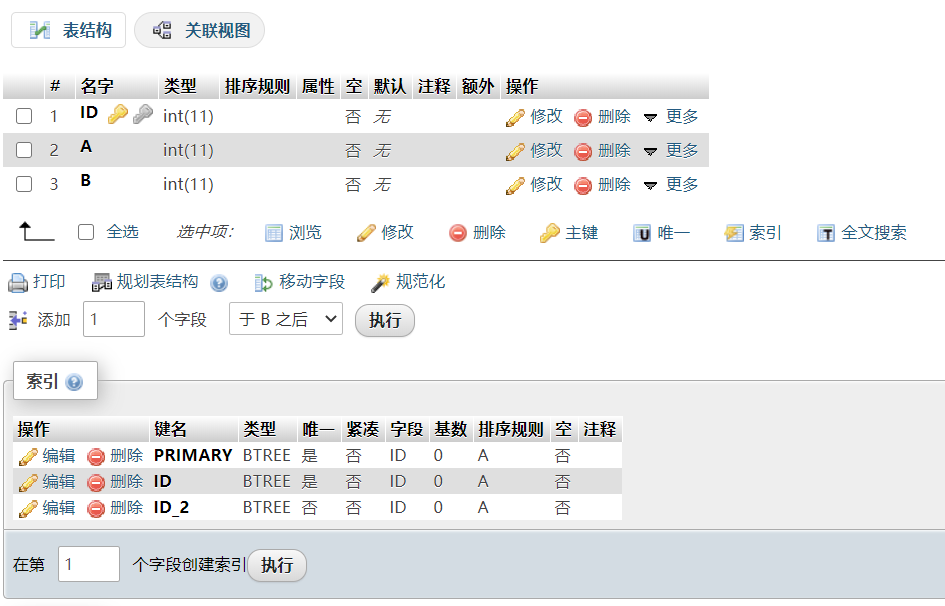
冗余索引是这样的,比如我们有了索引(A, B),又创建索引(A),那就是冗余索引。
另一种情况是将索引(A)拓展为索引(A, ID) ,这种情况也是冗余的,因为ID是主键,对于InnoDB来说主键列已经包含在二级索引中了。
大多数情况下都不需要冗余索引,应该尽量拓展已有的索引,而不是创建新索引。
但是拓展的时候也要小心,比如对 WHERE A=5 ORDER BY ID 这样的查询,在InnoDB引擎中索引(A)就相当于索引(A, ID)
如果我们拓展索引(A)为索引(A, B),那么实际上就变成了索引(A, B, ID),对上面的查询反而变慢了。
同时,表中的索引越多,插入,更新,删除就越慢。
未使用的索引
除了上面讲到的冗余和重复索引之外,还有一些服务器永远都不用的索引,建议考虑删除掉。
当然有一些索引功能相当于唯一约束,虽然没有被查询使用,但是也是有用的。
可以通过工具定位未使用的索引,然后删除。
索引和锁
索引可以让查询锁定更少的行。
InnoDB只有在访问行的时候才会对其加锁,而索引能减少InnoDB访问行的数量,从而减少锁的数量。
如果做全表扫描的话,则会锁住所有的行,那会更加糟糕。
另外InnoDB在二级索引上使用共享锁(读锁),在主键索引上使用排他锁(写锁)。